好久没更新了,正好上周遇到一个获取不到客户端IP的BUG,开发环境用nginx做反代都是work的。上到生产环境就获取不到。思来想去就是生产上多了一个SLB负载均衡。但这是一个老的功能,之前也都是好的,突然就拿的不对了,非常之诡异。
故障重现
为了确认不是代码的问题,我们使用tcpdump在服务结点上抓包。
1 | GET /api/foo/bar HTTP/1.1 |
发现报文头的X-Real-IP是一个VPC的内网地址,说明在我们的nginx中获取的$remote_addr就是10.130.0.1,是SLB的地址。
nginx配置如下:
1 | http { |
配置很简单,没有使用realip模块,直接将remote_addr认定为客户端ip。大家知道remote_addr不是http头,不容易伪造。它是服务端与客户端建立socket连接时,从客户端直接获取的。但是为什么这里获取的ip却是SLB自身的IP呢?
故障分析
再仔细分析抓包内容,发现其实报文中是包含客户端原始IP的,分别在x-forwarded-for和remoteip上。这里x-forwarded-for的值引起了我们的注意,如果是用nginx原始的$proxy_add_x_forwarded_for参数,客户端IP应该会放在最后,但是这里在第一位,说明SLB对这个头做过处理。
找到devops询问是否更改过SLB的配置,发现确实做过调整。为了直接在SLB实现http到https的重定向,将原本的4层负载均衡(tcp)换成了7层负载均衡(http)。试着将SLB恢复原有配置,可以获取客户端IP。最终问题定位到SLB的配置上。
再次阅读SLB手册,发现以下描述:
负载均衡提供获取客户端真实IP地址的功能,该功能默认是开启的。
四层负载均衡(TCP协议)服务可以直接在后端ECS上获取客户端的真实IP地址,无需进行额外的配置。
七层负载均衡(HTTP/HTTPS协议)服务需要对应用服务器进行配置,然后使用X-Forwarded-For的方式获取客户端的真实IP地址。
真实的客户端IP会被负载均衡放在HTTP头部的X-Forwarded-For字段,格式如下:
X-Forwarded-For: 用户真实IP, 代理服务器1-IP, 代理服务器2-IP,…
当使用此方式获取客户端真实IP时,获取的第一个地址就是客户端真实IP。
查看SLB配置页面确实也如文档所说
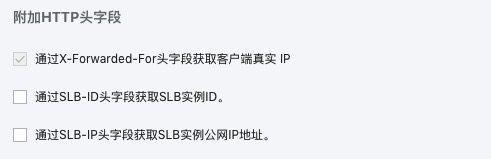
至于remote_addr获取到SLB的IP也就很容易理解了,当没有上级代理没有透传tcp连接时,remote_addr获取的就是上一层代理的ip地址。
故障恢复
既然定位到问题了,那么需要着手解决,改回4层LB是不现实的。
阿里云其实提供了两个方案:
- 按照文档上说的,获取X-Forwarded-For的第一段IP即为客户真实IP
- 通过抓包发现SLB会添加一个remoteip的头,直接使用就行
我们偷个懒,直接用第二种,在nginx将remoteip塞到X-Real-IP上,这样不用打hotfix即可修复问题。
花絮
其实在故障恢复的过程中,本想在本地复现的。过程就是用nginx搭建一个4层负载代理到7层负载最终到服务。如下图所示
1 | +------------------+ +----------------+ +---------------+ +----------------+ |
tcp负载的配置如下:
1 | stream { |
最终发现nginx的tcp代理有个巨大的坑,就是无法透传remote_addr,如果tcp代理跳过http直连服务,获取到的remote_addr就是127.0.0.1这个本机地址。
翻了翻文档,发现还真有官方说明
简而言之,就是要买nginx-plus,里面有个proxy_bind $remote_addr transparent;可以实现透传功能,满满的套路。
总结
DevOps有的时候真的会影响到业务,不同环境不同配置造成难以预料的影响。虽然我们的服务都已经实现了容器化。但是对于这些PaaS组件如何统一配置并且将配置代码化,让多个环境(包括开发,测试,staging)保持一致还是挺值得研究的话题。
