在做系统的整体性能测试时发现经常会卡在一个较低的QPS(单机低于100)数值,而且应用服务器的负载不高,检查MQ消费速率只有40左右。接着把目标放在消息发送端上,发现消息发送速率很低,大约40条/s。
果断搭建一个最小化工程单测Rabbitmq发送性能,发现在启用发送端事务后性能下降非常明显。
| 消息数量 | 开启事务 | 未开启事务 |
|---|---|---|
| 10w | 320796ms | 10246ms |
本机SSD硬盘测试结果10w条消息未开启事务,大约10s发送完毕;而开启了事务后,需要将近320s,差了30多倍。
接着翻阅Rabbitmq官网,发现开启事务性能最大损失超过250倍。
Using standard AMQP 0-9-1, the only way to guarantee that a message isn’t lost is by using transactions – make the channel transactional then for each message or set of messages publish, commit. In this case, transactions are unnecessarily heavyweight and decrease throughput by a factor of 250. To remedy this, a confirmation mechanism was introduced. It mimics the consumer acknowledgements mechanism already present in the protocol.
事务为什么会慢
1 | rabbitTemplate.setChannelTransacted(true); |
该标志位开启后表示Rabbitmq的发送统一被spring事务管理。当一段代码被@Transactional包裹,那么只有当事务结束后,消息才会正在的发送到Rabbitmq的exchange中。具体代码详见rabbitTemplate.java中的doSend()。
事务机制是Rabbitmq自身支持的,原理是channel.txSelect()开启事务,channel.txRollback()回滚事务。channel.txCommit()提交事务。当事务开启后,通过抓包会发现网络交互增多。
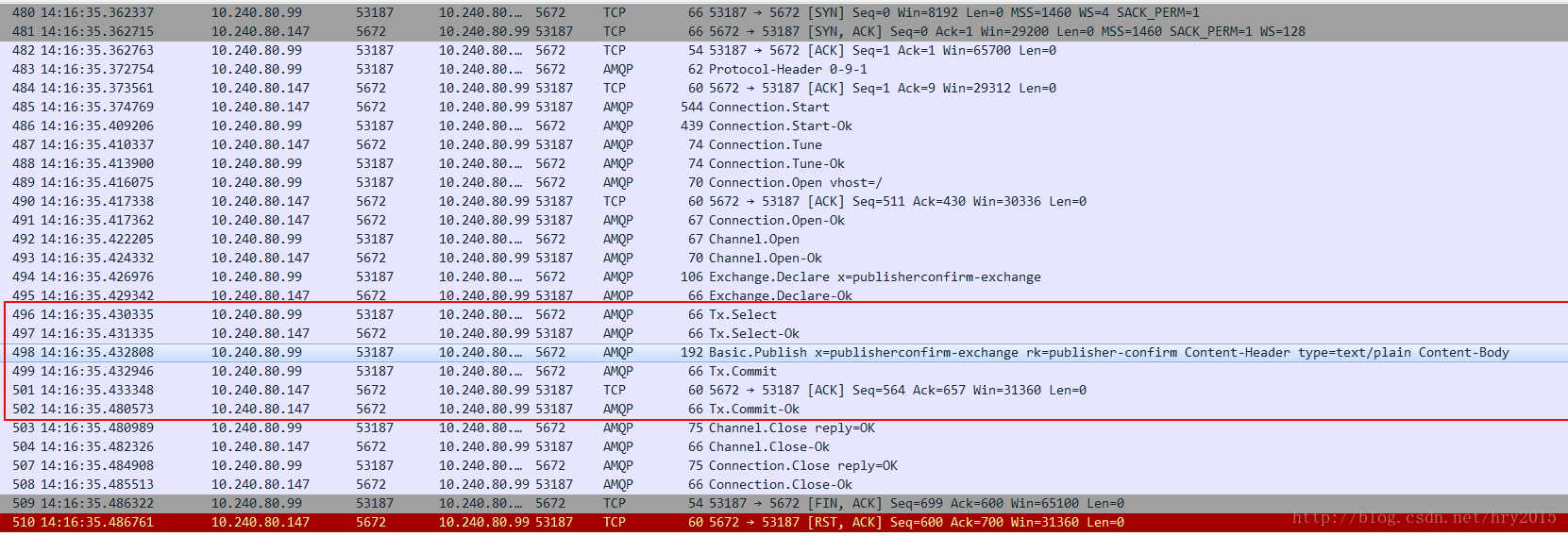
是否可以去掉事务呢?
实践证明,不行。
因为某些消息,特别是实体的新增或者更新消息发出后,消费者有可能会通过API反查,这时如果生产者本地事务未提交。消费者就有可能消费到空数据或者旧数据。所以生产者必须将发送消息的事务包裹在本地数据库事务当中。
在过去的实践中,有一种解法可以在不开启事务的情况下解决这个问题,就是利用本地消息表,即生产者调用后不发送,而是将消息写入到本地消息表,当事务失败那么此次写入操作也会回滚。真正发送消息到MQ就开启另一个定时线程轮询该本地消息表异步发送消息。这种方法理论上可行,但实际操作非常复杂,当有多个生产者实例时,定时发送线程也会有多个,那么就会遇到各种并发问题。
最大限度改善性能
既然无法去除事务,并且也不希望代码异常复杂。那么可以将消息分为两类,一类是changlog即实体的变化,一类是command,即通知消费者可以开始做某事,通常用在同步转异步的场景。对于第一类消息仍然保留事务,对于第二类消息关闭发送事务,采用PublisherConfirm的方式保证消息发送成功。
再次测试,性能明显提高,但是并未达到预期,通过innotop命令查看MySQL压力,发现只有10K/s上下。检查Rabbitmq所在机器的负载。
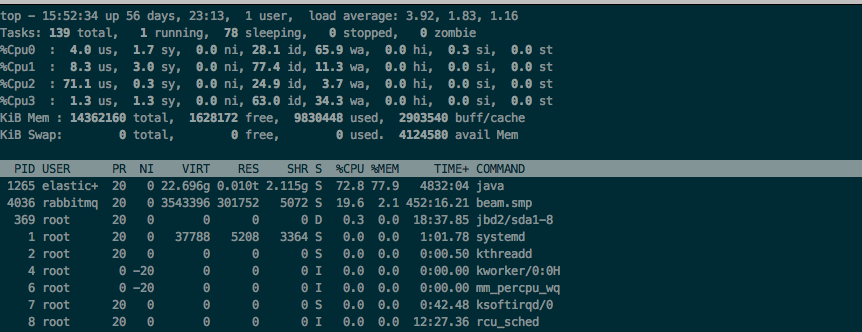
iowait非常高,由于该机器上还装有es,同样是io密集型的应用,所以实际性能瓶颈都在磁盘io上了。
跟Devops确认了机器情况,这台机器恰好是Rabbitmq的磁盘节点。为了快速验证,新增了一块SSD硬盘并将Rabbitmq消息文件都挂载到新加的磁盘上。再次测试,iowait下降明显。
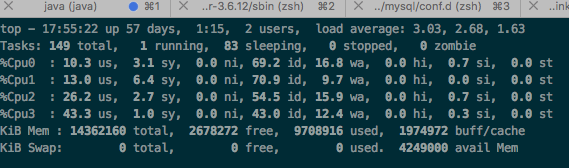
通过innotop命令查看MySQL压力,发现上升了一倍,达到20K/s。基本上把压力都转到了数据库一侧。系统整体性能提升了一个数量级。也许该Rabbitmq节点独占一台机器效果会更好。
总结
性能优化有时候就像破案,看了jstat没问题,gc没问题,机器负载也不高,就是抓不到“元凶”。需要一点一点的扣,往往一个短板就造成了木桶效应。另外还有一点就是如果硬件能够解决的事情,就不要过度优化软件了,代码复杂度上升往往意味着更多的BUG,在资源有限的情况下多花点钱省点时间还是值得的。
